페블러스는
'그린데이터'와 '데이터 그린하우스'를 통해
지속가능한 인공지능에 기여합니다.
데이터의 품질과
그로 인한 시장의 문제들
모호한 데이터 가격 체계, 모델 성능 저하, GPU 자원 낭비, 높아가는 AI 규제 대응 미흡
Problem 01
지속적이고 다양한
데이터 품질 문제
데이터의 구문, 의미, 분포의
복합적인 품질 문제
만성적인 데이터 부족과 잘못된
데이터 수집방향
Problem 02
AI 성능 저하 및
GPU 자원 낭비
낮은 데이터 품질로 인한
AI 성능 저하
모델 중심의 반복적인 학습으로 인한 GPU/에너지 낭비
Problem 03

강화되는 AI 규제 및 거버넌스 필요성
높아지는 AI 산업 규제 및 데이터 거버넌스의 필요성
데이터의 AI 적합성(AI-Ready Data) 요구 증대가트너 링크
페블러스의 해결 방안
Solution 01
AI 적합성을 만족하는
그린 데이터 Green Data* 제공
데이터 품질 평가 및 최적화를 통해 AI 적합성 기준을 만족하는 고효율 친환경 데이터 제공

Solution 02
데이터 그린하우스
Data Greenhouse* SaaS솔루션
데이터의 AI 적합성을 지속적으로 평가하고 개선하는 차세대 거버넌스를 위한 데이터 매니지먼트 솔루션
의미 기반 데이터 연산을 통한 그린 데이터 생성
의미 기반 데이터 관리 체계를 통한 효과적인
AI 산업 규제 대응
*그린 데이터 Green Data란?
데이터 품질 평가 및 최적화를 통해 AI 적합성 기준을 만족하는 고효율 친환경 데이터
*데이터 그린하우스 Data GreenHouse 란?
그린 데이터를 지속적으로 관리하는 데이터 거버넌스 솔루션
데이터 클리닉의 주요 특징
다양한 데이터 형식(Modality)을 지원합니다
텍스트, 이미지, 시계열, 정형 DB, 화학식, 멀티모달까지. 데이터 형식에 무관하게 품질 진단과 개선이 가능합니다.

다양한 산업 및 작업 도메인에
적용 가능합니다
모빌리티, 국방, 스포츠, 메타버스, 자원 재활용,
제조 물류, 제약/의료, 패션, 금융 등 데이터 클리닉은 다양한 산업 분야에 적용되고 있습니다.

정밀 타기팅을 통한 효율적인
합성데이터를 생성합니다
합성데이터, 역시 양보다는 질입니다. 페블러스는 데이터 클리닉 진단에 근거해서 데이터가 부족한 곳을 정확히 찾아낸 후 꼭 필요한 만큼의 합성데이터를 추가합니다.
DB의 정형 데이터도 데이터 클리닉
적용이 가능합니다
금융 및 의료 정보 등 중요한 정보들은 DB에 정형 형태로 저장됩니다. 데이터 클리닉은 정형 데이터에 대해서도 진단은 물론 재현 데이터와 결합성 평가를 제공합니다.

AI 학습데이터를
효율적으로 관리합니다
데이터 클리닉의 데이터 다이어트를 통해 효과적인 데이터 경량화가 가능합니다. 불필요한 데이터를 제거해 AI 학습데이터의 볼륨을 최적화하고 자원 효율을 극대화합니다.

데이터 품질은 설명 가능한
AI의 첫걸음입니다
윤리적이고 공정한 데이터셋의 사용 및 데이터 거버넌스 준수는 설명 가능한 AI의 시작입니다. 데이터 클리닉은 다양한 데이터 품질 기준을 지원합니다.
데이터 클리닉의
차별화된 기술
최신 딥러닝 신경망으로 구성한 데이터렌즈(DataLens)를
통해 인공지능 학습데이터의 다차원적 특성을
정밀하게 관찰할 수 있습니다.
AI 학습데이터 / 빅데이터
DataLens
* 'DataLens' '미국상표출원'

일반형
빠르게 도입 가능한
기성 딥러닝 신경망 이용

맞춤형
고객 데이터셋에 최적화된
딥러닝 신경망 이용
데이터 기하/통계 분석
데이터 간의 복잡한 관계와
패턴을 명확하게 드러내는
최신 알고리즘 기반의
기하/통계 분석 기술입니다
데이터 가시화
복잡한 데이터를 직관적이고
이해하기 쉬운 시각적 형태로
변환하여, 사용자 이해와
의사 결정을 강화합니다.
데이터 품질 개선
고유한 분석에 기반한 맞춤형
개선으로 데이터가 지닌 결함을 해결하며, 최적 품질의 데이터를 제공합니다.
핵심 기술의 지재권 확보
특허
• 국내 출원/등록: 35/7건
• 미국 출원/등록: 5/2건
• PCT 출원: 5건
논문
• 360° Reconstruction From a Single Image Using Space Carved Outpainting
(with POSTECH, SIGGRAPH ASIA 2023, Oral)
• Expandable Facial Expression Dataset via Embedding Analysis and Synthesis
(with GIANTSTEP, SIGGRAPH ASIA 2023, Poster)
• FacialX: A Robust Facial Expression Tracking System based on Multifaceted
Expression Embedding (with GIANTSTEP, SIGGRAPH ASIA 2024, Tech. Comm.)
왜 데이터 클리닉인가요?
10만개 데이터셋 기준
1시간 쾌속 품질 평가
AI 훈련 데이터셋의 품질 평가 및 시각화
5% 합성데이터로
2% 성능 향상
품질 진단 기반 정밀 타기팅 합성데이터 생성
80% 데이터 경량화로
x5 GPU 효율 향상
중복 데이터를 줄여 학습 효율 최적화
고객 데이터에 대한
품질 평가와 진단리포트
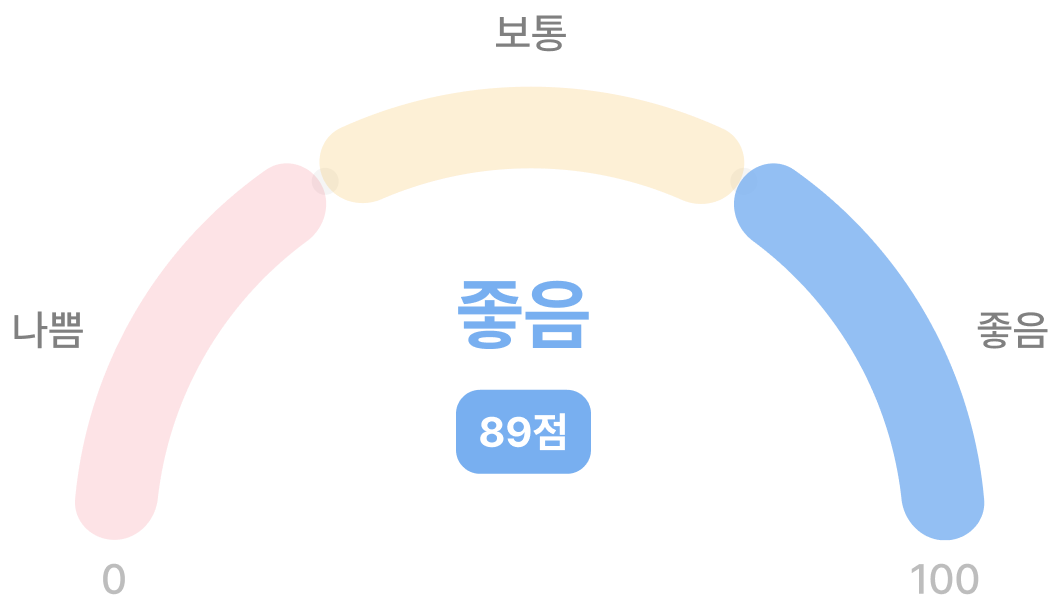
종합 평가
종합적인 관점에서 레벨 I, II, III 진단 결과를 종합하여 데이터 품질에 대한 평가를 하고 개선 방향을 제안합니다.
진단 결과 요약
진단리포트 발급일 2024년 09월 08일
Bird-450 데이터셋은 전반적으로 품질이 우수하지만 일부 개선이 반드시 필요한 부분이 있습니다. 데이터의 정합성이 우수하고 전체 이미지 개수도 충분하지만, 클래스 수가 많은 반면 개별 클래스의 이미지는 충분하다고 볼 수 없습니다. 아울러 일부 클래스의 다양성이 지나치게 높습니다.
품질 개선 제안
클래스간 경계가 뚜렷하지 않은 경우 합성데이터를 추가하여 클래스 간의 구별력을 높일 수 있습니다. (이는 트레이닝 데이터셋 뿐 아니라 테스트 데이터셋에도 해당됩니다.) 본 데이터셋의 경우, 클래스의 개수에 비해 클래스별 데이터의 개수가 상대적으로 적기 때문에 전체 대비 약 10%의 합성데이터를 추가하는 것을 제안합니다.
Data Bulk-up
데이터 벌크업

Data Repelica
데이터 레플리카
Data Diet
데이터 다이어트
진단 상태는 언제나 확인 가능
진단이 완료되면 메일 발송까지